What Time Should You Post to Reddit?
When posting anything on social media, whether a news article, a picture of yourself, or a funny image (or a combination thereof), you usually want to reach the largest audience. When posting on Reddit, I have noticed that the success of a post is largely determined by the time of day and day of week that your submission is posted. There are a few other factors, such as whether the post is an image, an article, or a text-only submission.
I have used the Python scraper I built in order to collect data on articles of particular Subreddits I wish to analyze. Among the data collected, I have...
The score of a post (roughly upvotes - downvotes)
The subreddit it was posted in
The time at which a post was made
The domain of the post's link
Using this information, I can formulate a model that describes what attributes affect the score. Specifically, I am looking for a percent change in the score with respect to values such as time of day, day of week, whether a post is an image post, etc. In my case, this can be approximated with this formula:
sign(score) * log(abs(score) + 1) = time_of_day_and_day_of_week + is_image_post + is_text_post + length_of_submission_title
I log-transform the score on the left side. Doing so ensures that the terms on the right side have a multiplicative effect on the score, as opposed to additive. The right side treats the time of day + day of week, the post being an image post, and its other attributes as independent factors that each scale the score by some value; i.e., I am controlling for other effects.
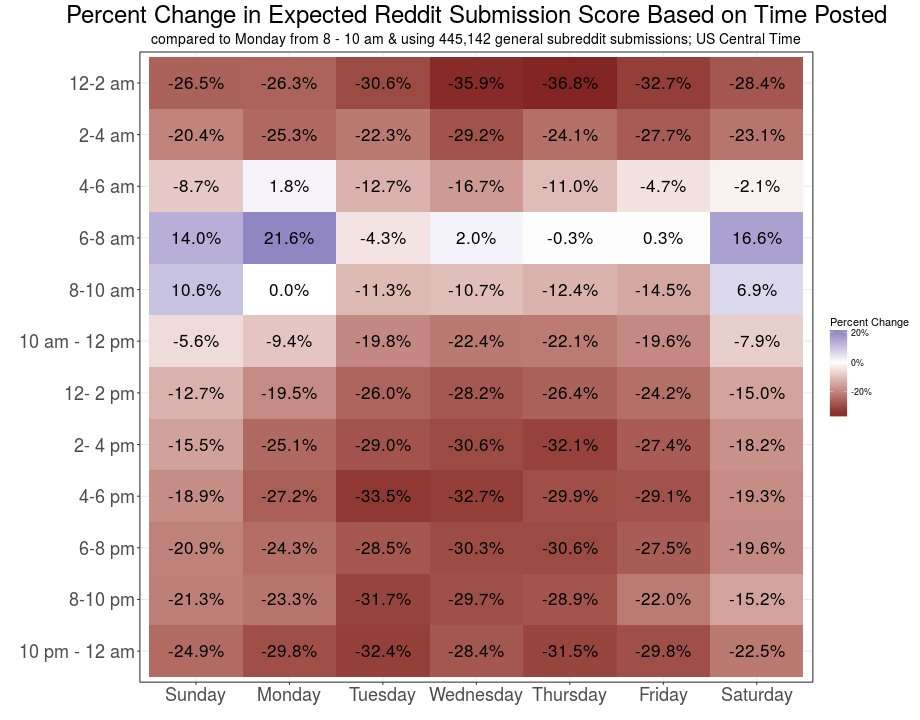
Below is a graph that estimates the effect of the time of day and day of week on six different subreddits I sampled collectively. I use Monday from 8 to 10 am as a reference, so the percentages are the percent increase in score you can expect if you post at the given time versus Monday from 8 to 10 am US Central Time .
Monday morning is a relatively good time to post in these subreddits, especially from 6-8 am. Sunday is even better during that time frame, with an expected score that is 74% higher than our reference, Monday from 8 to 10 am. Saturday, however, seems fairly strong most of the day.
Because the above image only applies to a relatively small amount of data, it helps to compare it to a different set of data. Below I sampled default subreddits, as well as thread commenter's comment histories, so this model generalizes to Reddit as a whole better.
This tells a similar story, except the tiles change a lot more smoothly. You could repeat the process, but the general takeaway is that the best time to post on Reddit is on Sunday, Monday, or Saturday from 6 to 8 am US Central Time. The next best times would be within 2 hours of that time range on those same days, or during that same time range on other days.
Technically, the transformation I made to the score adds 1 to the score before calculating the percent change, and negative scores are calculated as having points equal to 1/(1+abs(score)) , which is a fractional score always decreasing as the score becomes more negative.
Below I have the R code I used to generate the images. You can download the data for the file here: constrasts_threadmode.csv.
library ( plyr ) library ( dplyr ) library ( htmlTable ) library ( ggplot2 ) library ( scales ) setwd ( '/mydirectory/reddit_posting' ) #makes filenames possible/better subslash <- function ( x ){ x = ( gsub ( ' ' , '-' , x )) return ( gsub ( '/' , '-' , x )) } create_threads_plot <- function ( threads , tname = 'none' , subtitle_size = 18 ){ #group times to increase significance of data threads $ hour_ = cut ( threads $ hour , seq ( 0 , 24 , 2 ), include.lowest = TRUE , right = FALSE ) source_hour_ = levels ( threads $ hour_ ) target_hour_ = c ( '12-2 am' , '2-4 am' , '4-6 am' , '6-8 am' , '8-10 am' , '10 am - 12 pm' , '12- 2 pm' , '2- 4 pm' , '4-6 pm' , '6-8 pm' , '8-10 pm' , '10 pm - 12 am' ) threads $ hour_ = mapvalues ( threads $ hour_ , from = source_hour_ , to = target_hour_ ) threads $ titlelen = nchar ( as.character ( threads $ title )) / 100 threads $ logscore = sign ( threads $ score ) * log ( 1 + abs ( threads $ score )) threads $ is_self = with ( threads , ifelse ( is_self == 't' , 'Self Post' , 'Link Post' )) daysofweek = c ( 'Sunday' , 'Monday' , 'Tuesday' , 'Wednesday' , 'Thursday' , 'Friday' , 'Saturday' ) threads $ dow = factor ( daysofweek [ threads $ dow +1 ], levels = daysofweek ) weekday_hour_grid = expand.grid ( target_hour_ , daysofweek ) #make sure order is right weekday_hour_levels = paste ( weekday_hour_grid [, 2 ], weekday_hour_grid [, 1 ]) #for a better reference, ref=Monday 8-10 am weekday_hour_levels_ = c ( weekday_hour_levels [ 17 ], weekday_hour_levels [ -17 ]) threads $ weekday_hour = factor ( paste ( threads $ dow , threads $ hour_ ), levels = weekday_hour_levels_ ) #domain vars threads $ image_submission = factor ( c ( 'Image Submission' , 'Non-Image Submission' )[ 2 - threads $ domain %in% c ( 'imgur.com' , 'i.imgur.com' , 'i.reddit.com' )]) threads $ image_submission = relevel ( threads $ image_submission , ref = 'Non-Image Submission' ) #remove moderator posts, which will most likely be very high threads = threads %>% filter ( is_distinguished == 'f' , is_stickied == 'f' ) n_data_points = nrow ( threads ) #run linear model and extract coefficients model = lm ( logscore ~ weekday_hour + titlelen + is_self + image_submission + subreddit , data = threads ) model_summary = summary ( model ) coefs = model_summary $ coefficients #round sig figs for ( i in 1 : 4 ) coefs [, i ] = signif ( coefs [, i ], 4 ) #used to produce HTML output of the model summary for display on web sink ( subslash ( paste0 ( 'reddit_thread_summary_table_' , tname , '.html' ))) print ( htmlTable ( coefs )) sink () #now format matrix to show results coefmat = as.data.frame ( cbind ( varname = rownames ( coefs ), coefs ))[, 1 : 2 ] coefmat = coefmat %>% filter ( grepl ( 'weekday_hour.*' , varname )) coefmat = rbind ( data.frame ( varname = 'weekday_hourMonday 8-10 am' , Estimate = 0 ), coefmat ) coefmat $ dow = factor ( gsub ( '.*hour' , '' , gsub ( ' .*' , '' , coefmat $ varname ) ), levels = daysofweek ) coefmat $ hour = factor ( gsub ( '^[^0-9-]*? ' , '' , coefmat $ varname ), levels = rev ( target_hour_ ) ) coefmat $ `Percent Change` = ( exp ( as.numeric ( coefmat $ Estimate )) - 1 ) #save plot to png png ( subslash ( paste0 ( 'expected_reddit_score_' , tname , '.png' )), height = 720 , width = 920 ) print ( ggplot ( coefmat , aes ( x = hour , y = dow , fill = `Percent Change` )) + geom_tile () + xlab ( '' ) + ylab ( '' ) + #axes are self-explanatory with title ggtitle ( 'Percent Change in Expected Reddit Submission Score Based on Time Posted' , subtitle = paste ( 'compared to Monday from 8 - 10 am & using' , comma ( n_data_points ), tname , 'submissions' )) + theme_bw () + theme ( plot.title = element_text ( hjust = 0.5 , size = 24 ), plot.subtitle = element_text ( hjust = 0.5 , size = subtitle_size ), axis.text.x = element_text ( size = 18 , angle = 0 , vjust = 0.8 ), axis.text.y = element_text ( size = 18 )) + scale_fill_gradient2 ( labels = scales :: percent ) + geom_text ( aes ( label = scales :: percent ( `Percent Change` )),size = 6 ) + coord_flip () ) dev.off () } #load file and create a plot + html table for each threads = read.csv ( '/mydirectory/contrasts_threadmode.csv' ) create_threads_plot ( threads , 'nintendo/boardgames/rap/classicalmusic/democrats/conservative' , subtitle_size = 12 )
zonination on July 30th, 2017 at 13:46 UTC »
This is a popular topic here. However, instead of scraping, these guys used Reddit Bigquery:
http://minimaxir.com/2015/10/reddit-bigquery/ https://www.reddit.com/r/dataisbeautiful/comments/3nkwwa/the_best_time_to_post_to_reddit_east_coast_early https://www.reddit.com/r/dataisbeautiful/comments/3ozldw/the_best_times_to_post_to_reddit_revisited_ocOP, if you want some quicker turnaround on the scraping, a lot of the work has already been done and archived into Bigquery. TMYK
antirabbit on July 30th, 2017 at 12:02 UTC »
Where did the data come from?
I scraped the data using this scraper I made, which is based on PRAW and PostgreSQL. The default subreddit posts are from earlier this year in late January and early February. The random assortment from the six other subreddits came from last week.
How did you visualize the data?
I used R and ggplot2 for data cleaning and visualization. The exact code is highlighted at the bottom of the article. The raw data for the first image is also available here. The second file is a bit too large to share at the moment. If anyone really wants it and has any file sharing host suggestions, let me know.
imgur links to images
first image
second image
important note about data transformation
Since calculating a percent change with respect to 0 or a negative number doesn't make sense, I transformed all the data, so that
score = sign(score) * log(1+abs(score))In reality, the percent change is really the percent change in 1 plus the score. There are no negative values, apparently, so the sign() term doesn't do anything. Normally it would convert a negative score to a fraction (so it's still less than 0's new value of 1 before the log() is applied).
MotivationDedication on July 30th, 2017 at 11:56 UTC »
Highest percentage is between 6-8am on Sunday.
This is posted between 6-8am on a Sunday.....
Hmmm....